Modelling & Machine Learning (ML) Content
Modeling and Machine Learning
The main difference between modeling and machine learning is that modeling relies on predefined mathematical or statistical formulas to explain relationships in data, while machine learning automatically learns patterns from data without explicit programming. Modeling is often based on assumptions and is more interpretable, whereas machine learning is data-driven, flexible, and excels in handling complex, large-scale, and unstructured data like images and text.
There are two approaches in Machine Learning and Modeling Supervised and Unsupervised
In supervised learning, the data is typically divided into three subsets:
- Training Data: Used to train the model.
- Validation Data: Used during training to tune hyperparameters and evaluate the model’s performance to prevent overfitting.
- Test Data: Used after training to evaluate the final performance of the model on unseen data.
While in unsupervised learning:
- The entire dataset is often used for training because there are no predefined labels.
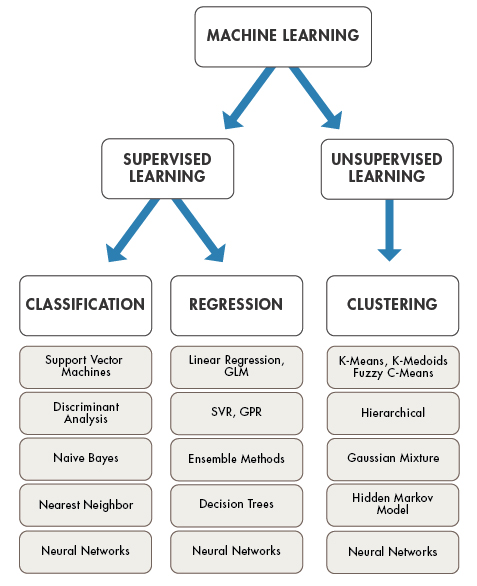
Supervised and Unsupervised Machine Learning Algorithms
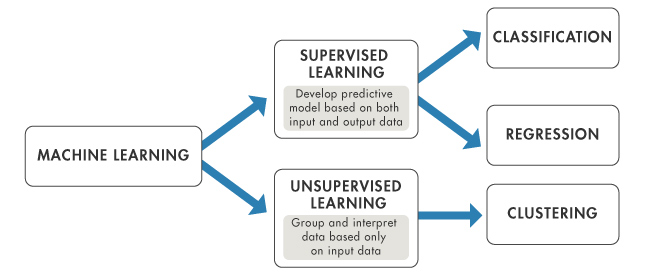
Examples of Supervised and Unsupervised Models
Learning Curve

Some Examples of Modeling Models that you will come across in my notebooks
→ 𝗥𝗲𝗴𝗿𝗲𝘀𝘀𝗶𝗼𝗻 𝗺𝗼𝗱𝗲𝗹𝘀
1️⃣ 𝗟𝗶𝗻𝗲𝗮𝗿 𝗿𝗲𝗴𝗿𝗲𝘀𝘀𝗶𝗼𝗻
Linear Regression models predict a continuous output variable based on one or more input features.
This model assumes there's a linear relationship between the input and output variables.
2️⃣ 𝗟𝗼𝗴𝗶𝘀𝘁𝗶𝗰 𝗿𝗲𝗴𝗿𝗲𝘀𝘀𝗶𝗼𝗻
Logistic regression predicts the probability of an outcome that can only have two values, like yes/no, 1/0.
We typically also put a threshold on the predicted probability to determine the predicted classification
→ 𝗧𝗿𝗲𝗲 𝗺𝗼𝗱𝗲𝗹𝘀
3️⃣ 𝗗𝗲𝗰𝗶𝘀𝗶𝗼𝗻 𝘁𝗿𝗲𝗲
Decision tree models look like flow charts; they help us make decisions based on a series of questions or input variables.
Decision trees can be used to classify data or predict continuous outcomes.
4️⃣ 𝗥𝗮𝗻𝗱𝗼𝗺 𝗳𝗼𝗿𝗲𝘀𝘁
Random Forest combines multiple decision trees to make predictions. It creates many decision trees using random subsets of the data and features.
This approach helps reduce overfitting and improves generalization.
→𝗖𝗹𝘂𝘀𝘁𝗲𝗿𝗶𝗻𝗴 𝗺𝗼𝗱𝗲𝗹𝘀
5️⃣ 𝗛𝗶𝗲𝗿𝗮𝗿𝗰𝗵𝗶𝗰𝗮𝗹 𝗰𝗹𝘂𝘀𝘁𝗲𝗿𝗶𝗻𝗴
Hierarchical Clustering is an unsupervised model that builds a tree-like structure of clusters.
They can be built from bottom up (each data point starts in its own cluster and clusters are merged as you move up the hierarchy) or top down (where all data starts in one cluster and splits occur as you move down the hierarchy).
→ 𝗜𝗻𝘀𝘁𝗮𝗻𝗰𝗲-𝗯𝗮𝘀𝗲𝗱 𝗺𝗼𝗱𝗲𝗹𝘀
6️⃣ K-nearest neighbors
KNN predicts outputs by finding the K most similar data points to a new input, and using their outputs to make a prediction. KNN is non-parametric, meaning it doesn't make assumptions about the underlying data distribution.
Some Examples of Machine learning Models that you will come across in my notebooks
1️⃣𝗞-𝗺𝗲𝗮𝗻𝘀 𝗰𝗹𝘂𝘀𝘁𝗲𝗿𝗶𝗻g
K-means Clustering is an unsupervised model that groups similar data points into K clusters based on their features.
It aims to minimize the distance between each data point and the cluster center.
2️⃣Principal Component Analysis (PCA)
It is an unsupervised statistical model primarily used for dimensionality reduction and feature extraction. Rather than making predictions, PCA transforms high-dimensional data into a smaller set of uncorrelated components (principal components) that retain most of the original data's variance.
1. LINEAR REGRESSION MODEL
- Linear regression with one variable using Scikit-learn
- Linear regression with multiple variables
- Using categorical features for machine learning
- Regression coefficients and feature importance
- Other models and techniques for regression using Scikit-learn
- Applying linear regression to other datasets
2. LOGISTIC REGRESSION MODEL
- Exploratory data analysis and visualization
- Splitting a dataset into training, validation & test sets
- Filling/imputing missing values in numeric columns
- Scaling numeric features to a range
- Encoding categorical columns as one-hot vectors
- Training a logistic regression model using Scikit-learn
- Evaluating a model using a validation set and test set
- Saving a model to disk and loading it back
3. DECISION TREES & RANDOM FOREST MODELS
- Preparing a dataset for training
- Training and interpreting decision trees
- Training and interpreting random forests
- Overfitting & hyperparameter tuning
- Making predictions on single inputs
4. GRADIENT BOOSTING MODEL
- Downloading a real-world dataset from a Kaggle competition
- Performing feature engineering and prepare the dataset for training
- Training and interpreting a gradient boosting model using XGBoost
- Training with KFold cross validation and ensembling results
- Configuring the gradient boosting model and tuning hyperparameters
References
Scikit-learn
Deep Learning for Computer Vision Content
What is deep learning?
Deep learning is a subset of machine learning that uses multilayered neural networks, called deep neural networks, to simulate the complex decision-making power of the human brain. Some form of deep learning powers most of the artificial intelligence (AI) applications in our lives today.
The difference between deep learning and machine learning is the structure of the underlying neural network architecture. “Nondeep,” traditional machine learning models use simple neural networks with one or two computational layers. Deep learning models use three or more layers—but typically hundreds or thousands of layers—to train the models.
Deep learning is an aspect of data science that drives many applications and services that improve automation, performing analytical and physical tasks without human intervention. This enables many everyday products and services—such as digital assistants, voice-enabled TV remotes, credit card fraud detection, self-driving cars and generative AI.
Face Detection with MTCNN (Multi-Task Cascaded Convolutional Networks)
NoteBook_1
Machine Learning Projects
1. Customer Churn Dataset
Dataset Description
Customer churn refers to the phenomenon where customers discontinue their relationship or subscription with a company or service provider. It represents the rate at which customers stop using a company's products or services within a specific period. Churn is an important metric for businesses as it directly impacts revenue, growth, and customer retention.
In the context of the Churn dataset, the churn label indicates whether a customer has churned or not. A churned customer is one who has decided to discontinue their subscription or usage of the company's services. On the other hand, a non-churned customer is one who continues to remain engaged and retains their relationship with the company.
Understanding customer churn is crucial for businesses to identify patterns, factors, and indicators that contribute to customer attrition. By analyzing churn behavior and its associated features, companies can develop strategies to retain existing customers, improve customer satisfaction, and reduce customer turnover. Predictive modeling techniques can also be applied to forecast and proactively address potential churn, enabling companies to take proactive measures to retain at-risk customers.
My Project in Logistic Regression, Decision Trees & Random Forest Models
Kaggle Competation
2. Predict the Introverts from the Extroverts
Dataset Description
The dataset for this competition (both train and test) was generated from a deep learning model trained on the
Extrovert vs. Introvert Behavior dataset. Feature distributions are close to, but not the same
as, the original. Feel free to use the original dataset as part of this competition, both to explore differences
and to see whether incorporating the original in training improves model performance.
Note – This is a relatively small dataset, so one to use for comparing different modeling approaches, making visualization, etc.
Files
train.csv – the training dataset; Personality is the categorical targettest.csv – the test dataset; your objective is to predict the Personality for each rowsample_submission.csv – a sample submission file in the correct format
Predict the Introverts from the Extroverts
Kaggle Competation
3. Regression of Used Car Prices
Dataset Description
About the Tabular Playground Series
The goal of the Tabular Playground Series is to provide the Kaggle community with a variety of fairly light-weight challenges that can be used to learn and sharpen skills in different aspects of machine learning and data science. The duration of each competition will generally only last a few weeks, and may have longer or shorter durations depending on the challenge. The challenges will generally use fairly light-weight datasets that are synthetically generated from real-world data, and will provide an opportunity to quickly iterate through various model and feature engineering ideas, create visualizations, etc.
Synthetically-Generated Datasets
Using synthetic data for Playground competitions allows us to strike a balance between having real-world data (with named features) and ensuring test labels are not publicly available. This allows us to host competitions with more interesting datasets than in the past. While there are still challenges with synthetic data generation, the state-of-the-art is much better now than when we started the Tabular Playground Series two years ago, and that goal is to produce datasets that have far fewer artifacts. Please feel free to give us feedback on the datasets for the different competitions so that we can continue to improve!
Files
train.csv – the training datasettest.csv – the test datasetsample_submission.csv – a sample submission file in the correct format
Regression of Used Car Prices
What is a Database?
A database is an organized collection of data that enables efficient storage, retrieval, and management of information. Instead of storing data in scattered files, databases allow for structured storage, making it easy to access and manipulate data efficiently.
Types of Databases
Databases come in various forms, including:
1. Relational Databases (RDBMS) – Stores data in tables with rows and columns. Example: MySQL, PostgreSQL.
2. NoSQL Databases – Designed for unstructured or semi-structured data. Example: MongoDB, Firebase.
3. Graph Databases – Used for representing relationships between entities. Example: Neo4j.
4. Key-Value Stores – Simple storage format for fast lookups. Example: Redis.
1. Introduction to Databases
- Databases definations
- Database Management System (DBMS)
- Types of Databases
- Relationships
- SQL Syntax and Structure
- SQL Data Types
- Installing MySQL
- Running MySQL
- Installing MySQL on Linux
Among these, Relational Databases are the most commonly used for structured data storage, and MySQL is one of the most popular RDBMS options.
Introduction to MySQL
MySQL is an open-source Relational Database Management System (RDBMS) used for managing structured data. It is widely used in web applications, businesses, and data-driven projects due to its reliability, speed, and ease of use.
SQL (Structured Query Language)
SQL is the language used to interact with MySQL databases.
In these notebooks, I will be working with MySQL databases and SQL.
2. Introduction to Relational Databases with SQL
- Use cases and design of relational databases and SQL
- Setting up a database locally using MySQL server
- Creating, modifying, and deleting databases and database tables
- SQL Data types and constraints (primary key, foreign key)
- CRUD (Create, Read, Update, and Delete) operations on tables
- Exporting and importing data from relational databases
3. CRUD Operations with SQL
- DDL (Data Definition Language)
- DML (Data Manipulation Language)
- CRUD Operations in SQL
4. Advanced SQL Techniques
- DQL (Data Query Language)
- Sorting and Filtering Data
- Complex Queries and Subqueries
- Data Control Language (DCL)
5. Adnamced Sql and Joins
- Aggregation, grouping, and pagination in SQL queries
- Mapping functions, arithmetic, and working with dates
- Combining data from different tables using SQL joins
- Improving query performance with indexes
- Executing SQL queries using Python and SQLAlchemy
6. Integrating Python with MySQL Databases
- Introduction to mysql-connector-python
- Working with Cursors
- Executing SQL Queries (SELECT, INSERT, UPDATE, DELETE)
A project On Kenya Online Market
Kenya Online Markets
This project showcases a responsive e-commerce platform built using modern web technologies, focusing on user experience and efficient product display.
Irura Jackson Mwongera is a Mathematician specialized in Data Science/Data Analytics with knowledge in website/system development.
Note:
- THIS WEBSITE WAS DESIGNED AND CREATED BY
[Irura Jackson Mwongera System/Website Design/Data Science Ltd]
Irura's Bio
Irura Jackson Mwongera is a diligent and versatile professional with extensive experience in data science, data analysis, web development, and data annotation.Irura's academic background includes a Bachelor of Science in Mathematics with Information Technology, specializing in statistics, from Masinde Muliro University of Science and Technology. He possesses a diverse skill set, including website front-end development (HTML, CSS, JavaScript), database management (MySQL, SQL), data analysis and visualization (Python, SQL, Excel, and Power BI), technical writing, data annotation, Machine Learning and deep learning for computer vision. His practical knowledge extends to basic computer maintenance, IT equipment installation, and data backup, making him a well-rounded and resourceful professional.In his personal life, Irura enjoys coding in Python, web development, watching football, socializing, researching, traveling, and seeking adventure. His hobbies reflect his curiosity and enthusiasm for continuous learning and exploration.
MY DATA SCIENCE & DATA ANALYTICS
Badges and Certificates
ALX AFRICA
Certificate For Professional Foundations
ALX AFRICA
Data Analytics
WorldQuant University
Applied Data Science Lab
WorldQuant University
Applied AI Lab: Deep Learning for Computer Vision
JOVIAN
Data Analysis in Python
JOVIAN
Machine Learning with Python